
随着国家经济的高速发展,对油气资源的需求越来越大,油气田开采力度不断扩大,油气井数量不断增加,集输管道里程持续增加,管道内部输送介质的腐蚀性加剧,使得与此相关的管道腐蚀问题越来越严重。腐蚀带来的管道爆裂、原油泄漏等问题严重影响了国家和企业的发展。原油和天然气为易燃、易爆物质,有时还含有硫化氢等有毒气体,石油与天然气管道始终是能源行业安全监管的重点领域之一。油气集输管道输送工艺和介质复杂、内腐蚀影响因素众多,腐蚀发生发展机制类型多样,例如塔河油田管道所处工况环境复杂,具有“五高一低”特点(高H2O、高CO2、高H2S、高Cl-、高矿化度、低pH),极易造成管道腐蚀与穿孔[1]。在管道轴向里程位置、管道环向时钟位置上,腐蚀的发生各具特点,多数情况下局部腐蚀的出现由多个因素或机制协同作用引起,这使得内腐蚀风险预测更为困难。
近年来,随着机器学习、人工智能等大数据技术的发展,机器学习技术逐渐进入工业领域,并在油气管道缺陷智能识别[2]、管道漏磁内检测、管道剩余寿命预测[3]等方面发挥着重要作用。MICHAEL等[4]基于油气田集输管道在线内检测数据训练贝叶斯网络,使用训练好的模型对没有在线检测数据的管道进行预测,结果表明,该贝叶斯网络模型可以对管道的内部腐蚀进行准确的预测。凌晓等[5]充分利用某输油管道检测数据集,针对反向传播神经网络(BPNN)模型的起始权值和阈值的优化问题,采用遗传算法(GA)进行参数寻优,有效克服了单一BPNN模型易陷入局部极值的问题,大幅提升预测精度,为管道完整性管理提供可靠的理论依据和决策支持。
作者以塔河油田历史失效数据为基础,利用皮尔逊(Pearson)相关系数和灰色关联度分析的方法明确管道内腐蚀主控因素,通过粒子群(PSO)算法对随机森林(RF)算法进行超参数优化,基于优化后的算法建立塔河油田管道内腐蚀风险预测模型,为油气田管道的腐蚀预警与防护提供帮助。
1. 管道内腐蚀影响因素
油气集输管道腐蚀的影响因素主要包括温度、CO2/H2S含量、水化学、流速、钢的成分和表面状态等,钢表面腐蚀产物性质会随着影响因素的变化而改变,从而对腐蚀速率产生显著影响[6]。
1.1 H2S、CO2含量的影响
当H2S和CO2同时存在时,H2S腐蚀和CO2腐蚀之间存在协同和竞争关系,腐蚀过程比较复杂[7]。SKILBRED等[8]认为,当系统中同时存在H2S和CO2时,可以根据其分压比p(CO2)/p(H2S)大致判断腐蚀主导因素是H2S还是CO2。当腐蚀过程以H2S的腐蚀反应为主时,主要产生各种类型的铁硫化物;当腐蚀反应由CO2腐蚀反应控制时,主要产生FeCO3;当腐蚀反应是两种气体腐蚀共同控制时,会同时生成各种铁硫化物和FeCO3。
1.2 温度的影响
温度对腐蚀的影响主要通过影响腐蚀产物的形成来实现。在不同环境条件下,随着温度升高,钢表面生成的腐蚀产物膜可能对腐蚀有促进作用,也可能有抑制作用。ABD等[9]使用HYSYS软件模拟了湿气管道的CO2腐蚀。当温度低于40 ℃时,由于碳酸铁层的高溶解度,管道表面没有形成保护膜,腐蚀速率随温度的升高而增大;当温度超过40 ℃时,管壁上形成致密的腐蚀产物膜,对基体起到保护作用,腐蚀速率降低。
1.3 pH的影响
SUN等[10]研究发现,pH可以通过影响电化学机制和表面保护性FeCO3膜的形成来影响碳钢的CO2腐蚀。在多相流工况下,当pH高于6.2时,钢表面能够形成保护性的腐蚀产物膜,因此pH升高能够明显降低腐蚀速率。MORAES等[11]的研究表明,pH升高会抑制H+的阴极反应,使Fe的阳极溶解减缓,因此腐蚀速率降低。此外,钢表面形成的碳酸盐腐蚀产物膜能够对钢基体起到保护作用,而溶液pH升高会抑制碳酸盐的溶解,进而降低腐蚀速率。
2. 基本原理
2.1 粒子群算法
作者采用粒子群优化算法对随机森林模型的超参数进行优化,该算法受鸟类捕食行为的启发,依靠群体智能随机搜索,通过粒子之间相互合作共享位置和适应度信息逐渐收敛到全局最优解[12]。如果将参数的最优解假设为其值域空间中一个兼具位置和速度属性的粒子,且寻优过程中的最优解由适应值(Fitness value)决定[13],具体迭代公式如下:
|
|
(1) |

|
|
(2) |
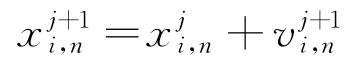
式中: 和
和 分别为粒子i在第j次迭代过程中第n维的速度和位置;
分别为粒子i在第j次迭代过程中第n维的速度和位置; 是粒子i在第n维中自身最优解的位置,
是粒子i在第n维中自身最优解的位置, 是群体在第n维中全局最优解的位置,每个粒子通过不断追踪这两个最优解进行更新;c1和c2为学习因子;rand(0,1)为由计算过程随机生成的(0,1)区间的随机数;w为惯性权重。
是群体在第n维中全局最优解的位置,每个粒子通过不断追踪这两个最优解进行更新;c1和c2为学习因子;rand(0,1)为由计算过程随机生成的(0,1)区间的随机数;w为惯性权重。
2.2 随机森林算法
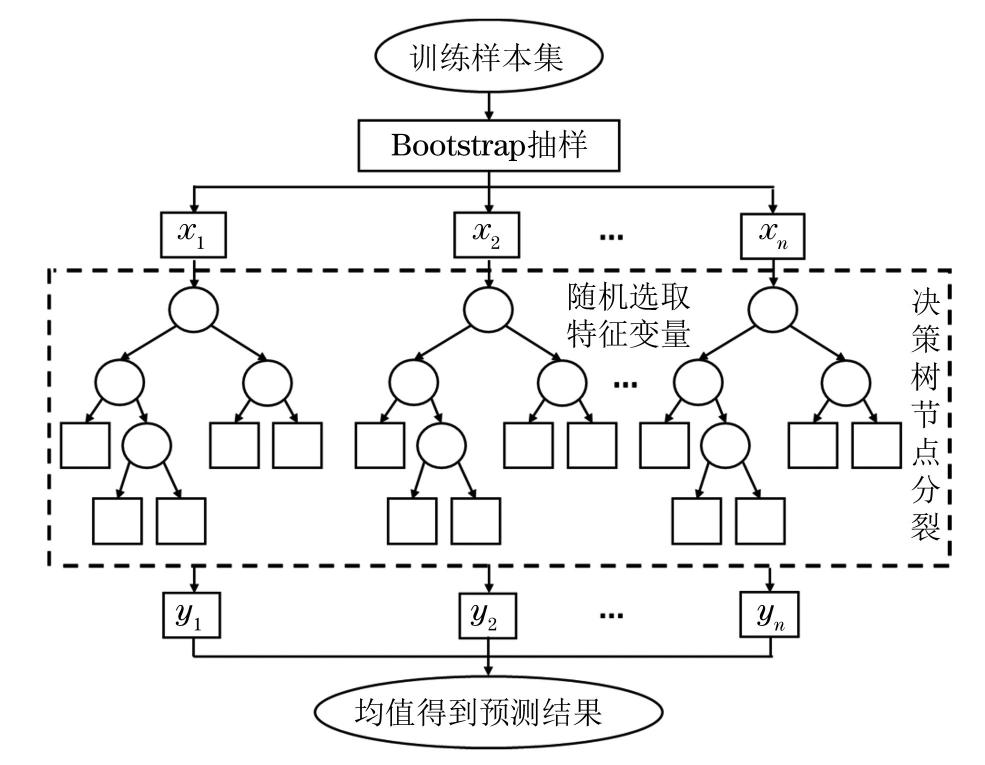
随机森林算法是一种高效且用户友好的集成机器学习技术,可用于开发预测模型,通常用于回归、分类以及特征选择问题。随机森林的概念最早在1995年由HO[14]提出,随后BREIMAN[15]在2001年提出随机森林算法并对该算法进行了系统阐述。随机森林模型在回归问题上应用广泛,可有效解决传统机器学习模型在训练和预测过程中容易出现的过拟合问题,与其他机器学习模型相比,其训练速度更快、鲁棒性更强、预测效果更好[16]。图1为随机森林算法的模型。
3. 建模流程
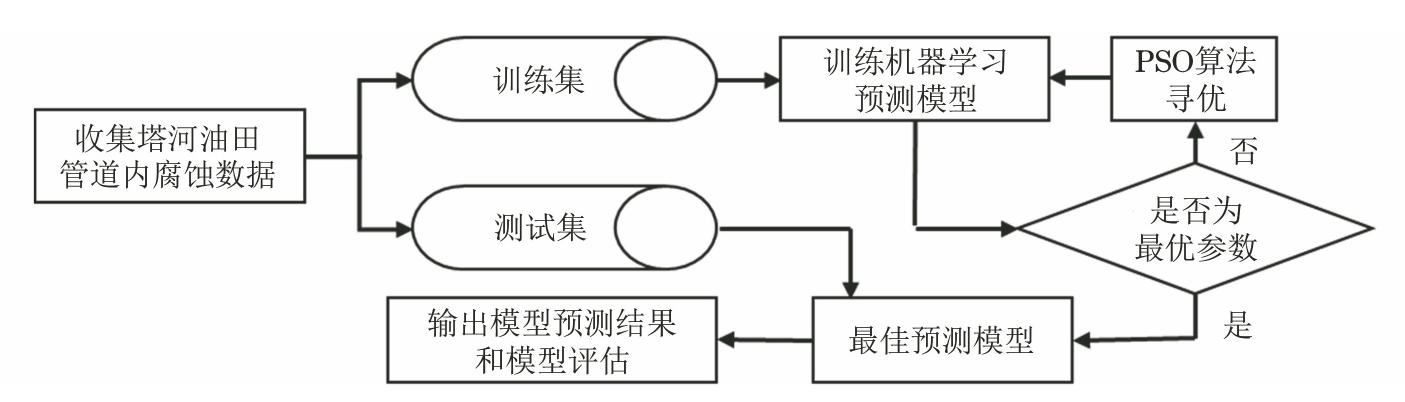
基于PSO-RF算法的管道内腐蚀风险预测模型(以下简称PSO-RF模型)的建模流程如图2所示。建模主要步骤包括:确定模型的输入输出变量;划分数据集为训练集和测试集;模型参数的优选和优化;模型训练和评估。
3.1 确定模型的输入输出变量
在建立的PSO-RF模型中,选择管道腐蚀速率作为模型输出变量,管道腐蚀影响因素作为输入变量。值得注意的是,样本数据在使用之前需经过归一化处理,以消除管道腐蚀因素数据集单位和维度的影响,提高获得最优解的速度,防止数据爆炸[17]。另外,考虑到某些特征如腐蚀影响因素与腐蚀速率的相关性较弱,即对腐蚀速率的贡献率较小,这些弱相关特征的存在会对模型的训练产生一定的干扰,导致模型泛化能力差,预测精度变低。故利用Pearson相关性分析和灰色关联度分析来确定影响腐蚀速率的主控因素,进而确定模型的输入变量。
3.2 划分数据集为训练集和测试集
数据集的划分对模型的训练和测试至关重要。在训练模型之前,首先使用sklearn库中的数据集划分函数train_test_split()对数据样本进行随机划分,训练集和测试集样本分别占总样本数的80%和20%,其中训练集用于训练和构建模型,测试集用于模型的预测和评估检验。
3.3 模型参数的优选和优化
对于随机森林算法而言,其超参数的选择将直接影响模型预测的准确性,而一般的网格搜索方法有一定的局限性,寻优次数较多且容易陷入局部最优解。为了尽可能缩小预测误差,找到全局最优解,作者选择粒子群算法对参数进行优选和优化,然后再使用随机森林算法对相关数据进行训练和预测。
3.4 模型训练和评估
最后使用训练集对PSO-RF模型进行训练,并使用测试数据集来评估模型的准确性。作者选择决定系数(R2)、平均绝对误差(σMAE)和均方根误差(σRMSE)来评估模型的预测精度[18],计算公式分别见式(3)~(5)。决定系数R2的值介于0~1,其值越接近于1,表示模型的拟合度越好,模型预测结果越准确[19]。
|
|
(3) |
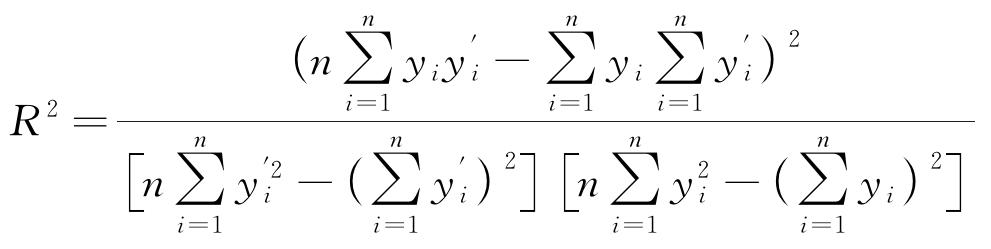
|
|
(4) |
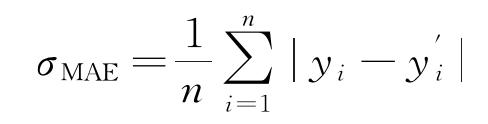
|
|
(5) |
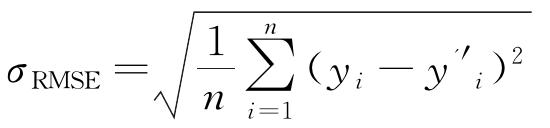
式中:n表示样本总量;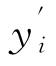 和yi分别表示测试样本的预测值和实际值。
和yi分别表示测试样本的预测值和实际值。
4. 实例应用
4.1 建立数据集
作者以Python编程语言为基础,使用Spyder.8软件进行编程。从塔河油田历年失效分析报告中的失效数据中共收集了603组数据作为预测模型的数据集。预测模型的输入变量为影响管道腐蚀的因素,包括以下六个方面:总压力、温度、H2S分压、CO2分压、Cl-含量和含水率。输出变量为管道在服役期间的平均腐蚀速率,利用首次穿孔刺漏时间、管线投产时间以及管线壁厚计算得到。表1为所有数据的范围及统计特性,使用最大值、最小值和平均值来描述。


